mknals programming (under construction) |

|
mknals programming (under construction) |
|
Since we have been using OpenTM2 with machine translation (TM) memories we have not been able to measure its quality. Also its quality has been a very controversial subject.
In this post we will try to explain how measure the quality of an openTM2 Machine Translation (MT) memory.
We will use a BLEU score implementation. BLEU is an IBM proposed metric (BLEU: Method for Automatic Evaluation of Machine Translation ( Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu / IBM T.J. Watson Research Cenver) that today is widely used in order to measure the quality of MT systems. There are several public sources (i.e. the MOSES statistical MT system) that provide BLEU score scripts.
The fact is that the BLEU score can help us as give us a ground, but it has to be used with care as it looks like internal (i.e. file type) or external (i.e. translator ignoring MT proposal) could have a big impact in the value. As usual, reality is always is more complex than a simple ratio, so usually you will need further investigation.
We have to remember that MT quality is a very important matter not only per se, in order to provide a good translation base (every day we hear less about translation and much more about "post-edition"), but from the economical point of view (the MT quality is often used as selling point for a more competitive price for customers/providers to justify prices (usually in the downward direction)). Experience tell us that many times quality expectaions have not been met.
There are many and different ways to measure the MT quality (BLEU, METOR or TER are widely known). One of the most used is BLEU. This score compares sentences from two sets, one as the reference set and the other one as the analysis set, searching differences between these sentences against groups of words ("n-grams") that belong to a "corpus". This corpus usually in simple implementations (multi-BLEU) belongs to the reference set itself. Its range is 0-1 (or 0-100%). The more close are the sets, the more close is the score to 1 (or 100%). Although is widely used, is not perfect, many articles in the internet can be found about its limitations.
In our case, to measure the MT quality:
These two sets are easily available in the OpenTM2 folders. The reference set (the translated info) is in the main translation memory (i.e., XXXX_SPA.EXP) and the analysis set (the MT proposed segments) is the TM memory (i.e., XXXX_SPA_MT.EXP) that is usually included in the initial folder. So, these two memories, the translator translation memory and the machine translation memory, are our starting point.
Our arrival point are 2 aligned text files, one file with translator single line segments, and other one with the matching machine proposed segments.
These 2 files will are then evaluated with the multi-BLEU script included in the MOSES statistical machine translation system. The multi-BLEU script is also available in other packages.
This BLEU score will tell us how similar are the MT proposals and what finally the translator has translated from those proposals. The more close are these set files, the best the resemblance/quality is, as this means that MT (what is proposed) is very similar to the translator choice (in otter words, the "correct" (or one of the "correct") translation. Be aware that if the translator just ignores maybe an almost perfect proposal and writes a different one of its own, it could hit the BLEU score.
The main steps are:
This process is explained if more detal in the Appendix A.
BLEU score ranges between 0 and 1 (or 0-100%), the higher the closest to an exact match between the 2 files set. It is important to understand that there is not an absolute reference for this score (we cannot say where the good and the bad quality/utility starts). But there are several clues:
- MOSES, the statistical machine translation system includes a baseline system that it is created with a 4,4 million words text corpus (a respectable value). The corpus is tag free. This corpus belongs to the news domain. This statistical only baseline system (without any rule) scores a 0,25 BLEU. Anyone who has installed it, will easily certify you that the system is far away from a useful solution.
- https://www.kantanmt.com provides a color graph where it looks like the border between red and green is close to 0,25.
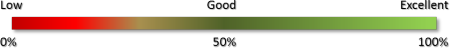
In the text looks like they are saying that a minim less than 0,15 is not acceptable. But obviously, this is a MT generator company. The same text states that a 0,5 would be "optimum". Anyway, this low value for an acceptable MT, maybe is providing us a clue that high scores are not easy to reach.
- I also would like to point out a work (Chapter 8 Evaluation - Statistical Machine Translation (www.statmt.org/book/slides/08-evaluation.pdf)) that tries to correlate a 1 to 5 human translation perception (Adequacy y Fluency) with the BLEU score. The translation human scale is set as:
| Adequacy | Fluency |
| 5 - all meaning | 5 - flawless English |
| 4 - most meaning | 4 - good English |
| 3 - much meaning | 3 - non native English |
| 2 - little meaning | 2 - disfluent English |
| 1 - none | 1 - incomprehensible |
and the subject work correlates this human perception with BLEU scores:
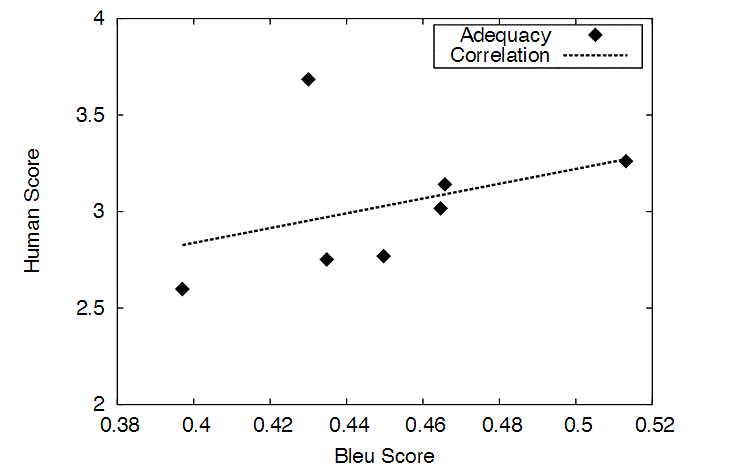
Again, looks like BLUE scores less than 0,38 probably will require hard post-editing tasks.
The main objective of this bullet is to explain how the BLEU score can help us to analyze results and how some obvious numbers can hide other results. These examples are only what they meant to be, examples.
Let say we have a MT provider (MTProv1), with 7 folders, and we run the steps. We could reach for instance these results:
| BLEU | MT/Src | All new | MT/Src | Words(aprox) | Notes |
| 48,26 | AAAAAABD004 | Y | MTProv1 | 107000 | md files |
| 32,12 | AAAAAABD006 | Y | MTProv1 | 46700 | md files |
| 31,78 | AAAAAABD007 | Y | MTProv1 | 16200 | fmd files |
| 34,37 | AAAAAABD011 | Y | MTProv1 | 16300 | md files |
|
|
|
|
|
|
|
| 33,09 | BBBBBABD002 | Y | MTProv1 | 105600 | dita files |
|
|
|
|
|
|
|
| 34,58 | CCCCCADD001 | N | MTProv1 | 11358 | dita files |
|
|
|
|
|
|
|
| 31,88 | DDDDDACP001 | Y | MTProv1 | 298553 | Several file types |
We can see that the score of MTProv1's MT is consistently in the 30-40 range. If we would like to evaluate MTProv1 as a one, we could weight the BLEU of each folder with the number of words (601711):
MTProv1 set BLEU score = (107000*48,26 + 46700*32,12 + 16200*31,78 + 16300*34,37 + 105600 * 33,09 + 11358 * 34,58 + 268553 * 31,88) / 601711
Will give us a "weighted" BLEU score of 35, 14.
In a similar way, the weighted standard deviation is 6,1.
Notice that the standard deviation is significative (even in the folders from the same project).
Let say we have another provider (MTProv2), and we do the same:
| BLEU | MT/Src | All new | MT/Src | Pal(aprox) | Notes |
| 67,36 | DDDDDABD003 | Y | MTProv2 | 101200 | Sparse tag dita |
| 69,9 | DDDDDABD004 | Y | MTProv2 | 79700 | Sparse tag dita |
| 70,52 | DDDDDABD005 | Y | MTProv2 | 20400 | Sparse tag dita |
| 55,45 | DDDDDABD006 | Y | MTProv2 | 58117 | Sparse tag dita |
| 71,86 | DDDDDABD007 | Y | MTProv2 | 202906 | Sparse tag dita |
|
|
|
|
|
|
|
| 39,42 | EEEEEABD170 | Y | MTProv2 | 53300 | md file |
| 47,68 | EEEEEABD030 | N | MTProv2 | 28850 | md file |
MTProv2 set BLEU score = (101200*67,36 + 79700*96.9 + 20400*70,52 + 58117*55,45 + 20296*71,86 + 53300*39,42 + 28820*47,68)/544473
Will give us a "weighted" BLEU score of 64,47
In a similar way, the weighted standard deviation is 10,61
Probably we should deduct that this provider (MTProv2 (64,47)) is much better than the previous one (MTProv1 (35,1)).
But you should proceed with care. Notice that in this case:
-standard deviation is much higher that in previous set. This is pointing us that probably the file type could be an important matter. Project DDDDD has very high values, maybe because the files have much less tags than an standard dita or md file. Deal with tags is a difficult task for MT systems.
- Notice that with heavy tags files (md or standard dita) the value is much lower (42,32) and much closer to the previous provider. If the last is true probably we could say that MProv2 is better (and not much better) then MTProv1.
- Even inside the same DDDDD project, there is a folder with a "low" score. Some explanation should be given. Maybe the translator is not using the MT memory?
- There is common project folder, DDDDDACP001, from the other provider, with a lower score (31) if we compare it against the folders DDDDDABD00x. Again, a quick view would let us think that MTProv2 is much better than MTProv1, but again you should proceed with care, as type file maybe has an impact.
So this examples show us you should proceed care and even though BLEU gives you an objective value, also:
- is pointing us that sparse tag files probably are eligible for a much better score
- if translator does not use the MT, the score could be worse (because probably the translation will not use the MT suggestion as base for an also correct/close translation).
The fact is that the BLEU score can help us as give us a ground, but it has to be used with care as it looks like internal (i.e. file type) or external (i.e. translator ignoring MT proposal) could have a big impact in the value. As usual, reality is always is more complex than a simple ratio, so usually you will need further investigation.
See the Summary.
BLEU (https://en.wikipedia.org/wiki/BLEU)
MOSES (http://www.statmt.org/moses/)
MT Talks http://mttalks.ufal.ms.mff.cuni.cz/index.php?title=Automatic_MT_Evaluation#BLEU
MT Talks http://mttalks.ufal.ms.mff.cuni.cz/index.php?title=Main_Page
MULTI-BLEU Score Interpretation (http://moses-support.mit.narkive.com/z10coOJo/multi-bleu-score-interpretation)
How BLEU Measures Translation and Why it Matters (https://slator.com/technology/how-bleu-measures-translation-and-why-it-matters/)
Description of BLEU Score for MT Quality (https://www.kantanmt.com/whatisbleuscore.php)Chapter 8 Evaluation - Statistical Machine Translation (www.statmt.org/book/slides/08-evaluation.pdf)
TFM Entrenament de motors de traducció automàtica estadìstica entre el castellà i el romanés especialitzats en farmàcia i medicina (Victor Peña).
Here we will try to run an step by step in case anyone dares to try it.
example_SPA.EXP
example_SPA_MT.EXP
On the other hand you will need
From the command line I extract the source and target info for the translator translation memory:
c:\Path\EXP2BiTextVB.exe example_SPA.exp
This will generate 2 files:
example_SPA_Source.txt
example_SPA_Target.txt
example_SPA_Source.txt will have English segments, i.e:
Seek personal success for themselves.
<strong>Open to change / Excitement</strong>
Emphasize independent action, thought, and feeling, as well
as a readiness for new experiences.
.
.
.
And the example_SPA_Target.txt the matching translator translations:
Buscar el éxito personal para sí mismo.
<strong>Apertura al cambio/Emoción</strong>
Destacar la acción, el pensamiento y los sentimientos independientes,
así como una disposición para nuevas
experiencias.
.
.
.
We will run the same for the MT memory:
c:\Path\EXP2BiTextVB.exe example_SPA_MT.exp
This will generate the English segment files and MT proposals:
example_SPA_MT_Source.txt
example_SPA_MT_Target.txt
MTEvalB_SrcTgt_Step2 will use as input the 2 set of 2 files. The first set will consist of the English segment/MT proposal:
example_SPA_MT_Source.txt
example_SPA_MT_Target.txt
The second set will consist of English segment/translator translation:
example_SPA_Source.txt
example_SPA_Target.txt
The problem we have to face here is match English segment with both the translator translation and the MT proposal. In order to do so, the program will use a temporary database to load all these files.
Once this is done, the program will read the temporary database and create the final set, one file with the translator translation segments and another one with the TM proposals. The command line should be like:
c:\Path\MTEvalB_SrcTgt_Step2 c:\Path2\
example_SPA_MT
c:\Path2\example_SPA
Cleaning sentences table. 2359 deleted
Reading Source and Target machine proposal:
U:\usr\pro\VS2008\Prod\MTevalB\test\example_SPA_MT_Source.txt
U:\usr\pro\VS2008\Prod\MTevalB\test\example_SPA_MT_Target.txt
.........*.........*.......
End prcocessing MT files
Starting processing transaltor files
Reading Source and Target from translator proposal:
U:\usr\pro\VS2008\Prod\MTevalB\test\example_SPA_Source.txt
U:\usr\pro\VS2008\Prod\MTevalB\test\example_SPA_Target.txt
.........*.........*.........*.
End processing translation files
Creating otput files por BLEU score
Starting processing transaltor files
End Process
The following files should be created:
U:\usr\pro\VS2008\Prod\MTevalB\test\example_SPA_Tgt_BLEU_MT.txt
U:\usr\pro\VS2008\Prod\MTevalB\test\example_SPA_Tgt_BLEU_Trad.txt
The following files will be created:
c:\Path2\example_SPA_Tgt_BLEU_MT.txt (Target (SPA) MT
proposals)
c:\Path2\example_SPA_Tgt_BLEU_Trad.txt (Target (SPA)
Translator translations)
As we have the reference file (what the translator has translated) and the analysis file (what the machine has proposed), we are ready to run then BLEU score.
As stated previously there are several sources of the multi-BLUE script, in my case an ubuntu linux machine with the perl script. BLEU score is based in the "n-grams" search in the corpus reference. As we do not have the whole corpus, we have to rely only with the translator translation only. So the biggest is the reference file, the better will be the score reliability. In my case I copy the files to the linux machine.
I run the multi-bleu.perl terminal command (the output is redirected to a BLEU.txt
file):
~/mosesdecoder/scripts/generic/multi-bleu.perl
example_SPA_Tgt_BLEU_Trad.txt < example_SPA_Tgt_BLEU_MT.txt >
BLEU.txt
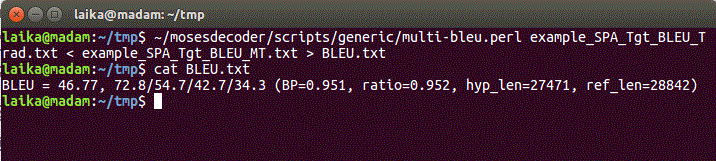
The file BLEU.txt will have the results:
BLEU = 46.77, 72.8/54.7/42.7/34.3 (BP=0.951, ratio=0.952,
hyp_len=27471, ref_len=28842)