mknals programming (under construction) |
 |
mknals programming (under construction) |
|
In this post I will try to compare two known solutions in the open source world for machine translation, Moses and OpenNMT.
Moses is a statistical machine translation system (SMT) that also allows you to include linguistic information (http://www.statmt.org/moses/). In this post we will use an out of the box configuration. Plain Moses.
OpenNMT is an open source (MIT) initiative for neural machine translation and neural sequence modeling that comes from the Harvard University NLP group and SysTran (http://opennmt.net). I also will use an out of the box configuration, the OpenNMT-lua configuration. Again, plain OpenNMT.
Both systems somehow try to learn comparing the proximity of words in two languages in order to find out a correct translation solution, in the neural case in a much more extensive way.
I have used the following corpus:
- Moses baseline system News corpus for the English<>Spanish (EN<>ES) (as it is in the Moses baseline system)
- Europarl corpus for the Portuguese<>Spanish (PT<>ES) (with some cleaning)
- Diari Oficial Generalitat de Catalunya for the Catalan<>Spanish (CA<>ES) (with some cleaning)
The main objective has been to run several tests with the same corpus files in a statistical machine translation (MOSES) and in a neuronal machine translation (OpenNMT) in order to find if there is a major difference between these two technologies.
The main metric for compare it has been the multi-bleu score perl script used in MOSES. This controversial metric (that it is said that is far from to be perfect) is a very wide used metric that at least can be use as indicator comparing results.
If you only are interested in the results, read this section only.
The first "surprise" is that Moses (SMT) and OpenNMT (NMT) BLEU scores have very similar. Conclusion: you cannot expect a leapfrog jump between NMT and SMT technologies. At the end looks like the underlying technology is similar.
The second "surprise" is that all feedback we are hearing/experiencing is that neuronal is better than statistical MT. If so, why BLEU scores are almost the same? Does it mean that BLEU is not a valid score? Or indeed the results are similar? This remains an open issue, maybe BLEU score is not a valid metric for NMT quality. This is very important matter, as in many places or papers, minimal BLEU changes are used as burden of proof that some new procedure/enhancement is better than other one.
We have used a very similar languages corpus (CA<>ES and PT<>ES). Common sense tells us that BLEU scores should be very similar. But, "surprise", for CA<>ES BLEU we have reached scores over 85% and for PT<>ES only less than 40%. The reason is obvious, the corpus. For the CA<>ES we have used a reliable source (the official CA/ES goverment announcements (DOGC)) and for the other, the PT<>ES a bulk corpus from the European Parlament. So, the conclusion is so obvious that often is forgotten: if you want good results, no matter SMT nor NMT, probably the most important factor is a good corpus.
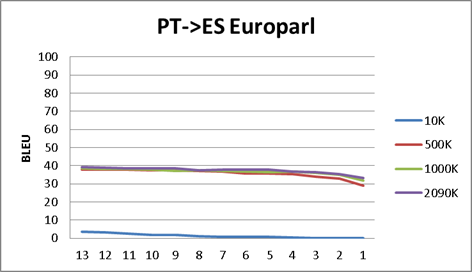
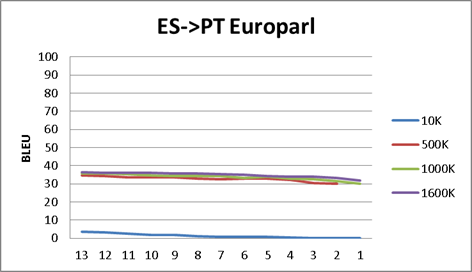
For OpenNMT only: Also is interesting to notice, that beyond
some point, increasing the corpus size does not increase (very much) the
BLEU score. 500K, 1000K or 2090K lines corpus have very close BLEU
scores. Same for epochs, after initial epochs (4-5), BLEU scores do not
dramatically change. This is important as can save you time for the
machine/GPU demands. Conclusion: You can get some sense of the final
results without the whole corpus.
I have run some basic test EN<>ES with the MOSES data, and with a more extensive corpus for ES<>CA and ES<>PT. The sources for these are:
3.1 EN<>ES News-commentary corpus (MOSES bases training/tunning/verification data)
The source of this corpus is the MOSES web page. This corpus is used to test the MOSES baseline system. All these can be found in http://www.statmt.org/moses/?n=Moses.Baseline
- news-commentary-v8.es-en 174K lines (aprox) -> main corpus
- news-test2008 for tunning 2K lines -> training data
- newstest2011 for verification 3 K lines -> verification data
3.2 ES<> PT Europarl v7 Corpus
The Europarl parallel corpus is extracted from the proceedings of the European Parliament by the MOSES team (Philipp Koehn) (Europarl: A Parallel Corpus for Statistical Machine Translation ->
http://homepages.inf.ed.ac.uk/pkoehn/publications/europarl-mtsummit05.pdf. It also can be found at http://opus.nlpl.eu/Europarl.php. The page provides a bitext (http://opus.nlpl.eu/download.php?f=Europarl/es-pt.txt.zip) in order to be used for MOSES.
- es-pt.txt_moses (Europarl.es-pt.es/pt) -> 1932K lines (Around 100M words)
3.3 ES<>CA Diari Oficial Generalitat Catalunya (DOGC)
Documents from the official journal of the Catalan Goverment in Catalan and Spanish provided by Antoni Oliver Gonzalez from the Universitat Oberta de Catalunya.
Extracted from http://opus.nlpl.eu/DOGC.php
ca-es.txt.zip -> 10933K lines ( 167M words )
4 Data preparation - Cleanup
I have created a couple of programs in order to run some tasks (when needed), that are:
Limpia -> this program removes some lines after hardcoding some
rules.
Reductor -> this program splits evenly a bitext file pair in smaller
ones in order to create the corpus, the training data and the verify
data.
BitTextDupRemoval -> Removes duplicated lines from a bitext pair
files.
Not sure if I will be able to find some time to place somewhere these files, if anyone is interested, pls, ask it to infomknals@gmail.com
4.1 EN<>ES News-commentary corpus
No clean up, used at it is.
4.2 ES<> PT Europarl v7 Corpus
This corpus is a little bit peculiar as there are multiple language sources that are converted to many other languages. Not sure if there are direct translations or just everything is translated first to English. The corpus was originally 2635K lines
We run some cleanup:
- Remove all lines very short
- Remove lines with ), ~, /, - (We want plain sentences)
- Remove lines with very different lengths
(In the cleanup code, there is a very basic flter).
The cleanup shrank 88% the original corpus up to 1701K lines
Next step was to remove duplicate lines (BitextDupRemoval). Line count -> 1692K lines
Being sure that no duplicate lines were in place, we divided (evenly) with a program (Reductor.exe) in 3 different sets:
Europarl_Base.pt - Europarl_Base.es -> main corpus 1694K lines
Europarl_TUNNING.pt - Europarl_TUNNING.es -> 5K lines
Europarl_VERIFY.pt - Europarl_VERIFY.es -> 3K lines
4.2 ES<> ES<>CA Diari Oficial Generalitat Catalunya (DOGC)
We did some cleanup as many sentences looked problematic. As the corpus was big (10 million lines), we took some drastic clean up decisions.
Same as ES<> PT plus
- Removes all lines that do not end with . (dot) , (comma) or : (colon) (We want sentences)
This cleanup is huge, for the DOGC, only 30% of lines were worth. 3384K lines
Next step was to remove duplicate lines (BitextDupRemoval). Line count -> 2161K lines
We also remove at the end of the corpus an ordered term list. Final line count -> 2146K lines
Being sure that no duplicate lines were in place, we divided (evenly) with a program (Reductor.exe) in 3 different sets:
DOGC_Base.ca - DOGC_Base.es -> main corpus 2138K lines
DOGC_TUNNING.ca - DOGC_TUNNING.es -> tunning 5K lines
DOGC_VERIFY.ca -> verify 3K lines
MOSES already provides some scripts in order to prepare data. The same prepared data was used for OpenNMT.
The 3 corpus x 2 language pairs have been prepared in the same way, using Moses cleanup scripts.
1) Tokenisation (tokenizer.perl). This script add spaces between words and punctuation
2) Truecasing. There are 2 steps:
2a) Truecaser training (in order to extract statistics about the text from the full corpus with the MOSES' train-truecaser.pel) and
2b) The actual truecasing (truecase.perl).
3) Cleaning is used to remove long sentences, sentences are limited to 80. (MOSES' clean-corpus.perl). We only have used the cleaning for the MOSES testcases.
6.1 EN-US full corpus (172K lines)
| Language pair | BLEU MOSES | BLEU OpenNMT |
| EN->ES | 25,61 | 24,93 |
| ES->EN | 24,28 | 20,66 |
6.2 ES->PT full corpus 1694K lines
| Language pair | BLEU MOSES | BLEU OpenNMT |
| PT->ES | 38,82 | 39,08 |
| ES->PT | 36,39 | 36.25 |
6.3 ES→CA full corpus 2090K
| Language pair | BLEU MOSES | BLEU OpenNMT |
| CA->ES | 89,13 | 85,42 |
| ES-> CA | 88,72 | 85,45 |
6.4 Summary
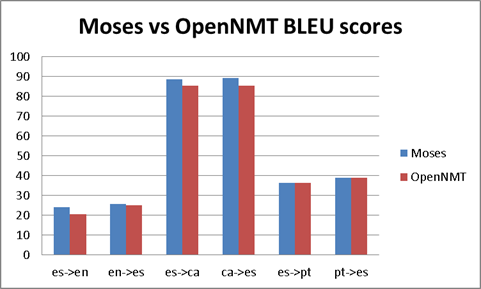
| Moses | 24,28 | 25,61 | 88,72 | 89,13 | 36,25 | 38,82 |
| OpenNMT | 20,66 | 24,93 | 85,45 | 85,42 | 36,25 | 39,08 |
| Pair | es->en | en->es | es->ca | ca->es | es->pt | pt->es |
Notice that ES<>PT Europarl results have acceptable BLUE scores (36-39), but ES<>CA DOGC (85-89) excels.
- Moses/OpenMT BLEU scores are very similar. This is an interesting fact as somehow reveals that the statistical nature that underlies below both solutions is the same. You cannot expect a leapfrog jump between these two technologies.
- Moses scores are (a little bit) better than OpenNMT. This is somehow disappointing, but is not new. In the recent OpenMT 2018 workshop in Paris, Tony O'Dowd (KantanMT), also shared with us similar results. The point here is that, or BLEU score is not a good ratio for quality comparison, or OpenNTM is not much better than Moses.
- There is also a very (obvious) interesting result. The EN-ES News corpus probably is too small to raise any conclusion, but, the CA-ES and PT-ES are not minimal. The point here is that CA-ES-PT are very close languages, so, why there this huge difference between ES<>CA and ES<>PT BLEU scores (around 40 points)? Obviously the reason is the corpus. Europarl corpus raises some questions about how is created. For example, we are not sure if the different versions are bridged thru English language. (I.e., maybe a czech speaker is translated to English and from English to all the other languages), or for example, maybe some speeches are not in the speaker mother tongue. Something is preventing the Europarl to reach good scores in a very similar language. On the other hand, we have a reliable corpus (ES<>CA) as the one provided from the local Catalan government. This corpus it should be mainly in CA, and then translated to ES. This corpus is providing us outstanding BLEU scores (near 90). So again, even it is obvious, if you want good results, you need a good corpus.
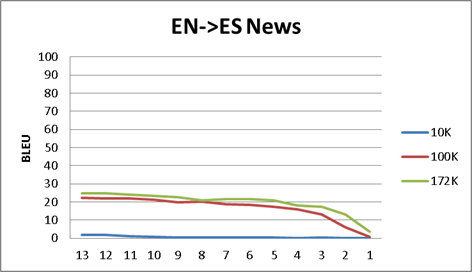
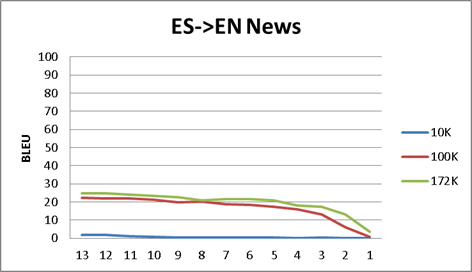
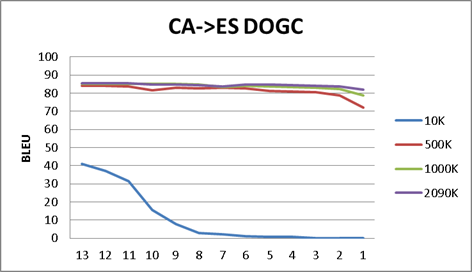
- We have run some tests in order to find how the number of lines in the training bitext files affects the final BLEU score. Thru the results of the Appendix A, we have found that, after running with OpenNMT a minimal bitext size (for example 100K lines), you cannot expect a huge increase with a much larger same nature corpus. The point here is that you do not a huge corpus in order to get a "flavor" of what can be achieved. (We do not include here, but same is true with Moses).
- As for the OpenNMT interim results (in each epoch), you also cannot expect a huge increase in the BLEU value after the second or third epoch run. Again, if you just want to get a "flavor" of the final results, probably you could miss several epochs.
The consensus that NMT is better than SMT, cannot be countersigned here with the BLEU score.
Appendix A - Different corpus size and epoch by epoch BLEU scores
I do not include here the actual data, just the graphics:
- Each graphic is a language pair (ES<>EN news corpus, ES<>CA DOGC corpus, ES<>PT Europarl)
- We have run OpenNMT process with different corpus size (i.e. 10K, means 10000 lines corpus bitex).
- We have translated the verification text with the result of each epoch model and score it against the reference text in each language.
- The x-axis is the epoch number

ToDo