mknals programming (under construction) |
 |
mknals programming (under construction) |
|
The purpose of this application is to identify the most probable
language of a <target>target sentence</target>
in an xliff, and then create an excel output file with the confidence
of each sentence. The confidence value is issued by the IBM Watson
Translator offered on IBM Cloud.
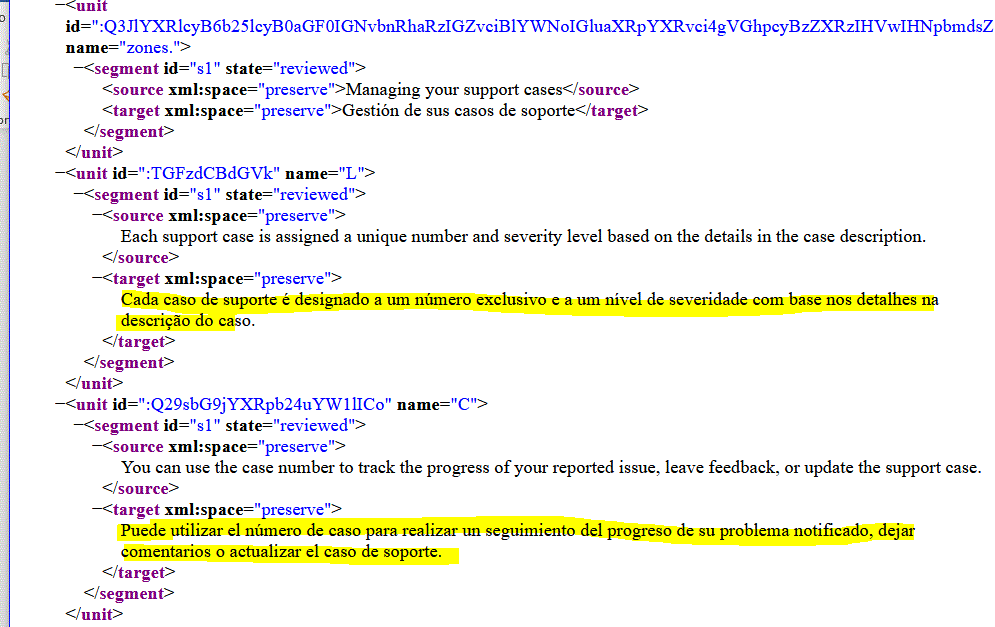
Usually, all target sentences in the xliff should be of the same target language, but due some errors, file could be ended with a mix of languages. This program, will identify these sentences.
Here an example of the xliff with mix of PT and ES in target sentences.
Usually, due the large number of words, does not look a good option to manually inspect the full file, so DL/AI is good option here to use a "language identification". Several services offer language identification, as the Google’s Cloud Translation (https://cloud.google.com/translate). But in is proposed solution we will use the IBM Watson Language Translator that is offered in IBM Cloud (https://cloud.ibm.com/apidocs/language-translator).
Using python, the main steps will be:
<source>
and <target>. Using these handlers we will get
the source/target content. XML.SAX is supported by default in
python.<target> content
(the sentences we want to find the most probable language), to the
IBM Watson Language Translator. The service will return a json file
with languages ordered by confidence. "languages" : [ {
"language" : "es",
"confidence" : 0.9955377581001156
}, {
"language" : "it",
"confidence" : 0.002488014556859667
}, {
"language" : "eo",
"confidence" : 5.747564458215991E-4
.
.
Final result is an excel very similar as this one (in this screen capture, only format has been changed). Notice how the Excel can easily allow as to find what are the trouble segments. This allows solve in large the issue. Notice in the screen capture, the most probable ES or PT pair and the confidence.

Requirements:
-In order to run this, you need an IBM Cloud account (free) and IBM Watson Language Translator (Lite version free) in IBM Cloud. Credentials are stored in the code.
Originally published in https://github.com/miguelknals/xml-sax-parser-4-xlif.